Predictive analytics using Corda
November 14, 2018
Predictive analytics using Corda

Distributed Ledger Technologies are not just here to stay, they are here to shape the future of Information Technology. There has been a significant leap in the evolution of DLT in the past 3 years in terms of its capabilities and 2018 was the year to see the first finalised products in the financial services industry. Outside financial services the public sector is also starting to move beyond use case definition and into prototyping and development. For example, the UK Land Registry Digital Street project aims to explore how DLT and smart contracts can make the property buying / selling process simpler, faster and cheaper. For this project Blockchain Digital is working with the Land Registry to develop Corda Applications and build an innovation eco-system comprising of estate agents, conveyancers, banks, HMRC and wider industry participants; It is a unique period of digital transformation and the year 2019 will be the year to see it all coming into place. We expect rich enhancement of the DLT technology stack and delivery of important products in all sectors including trade finance, supply chains, healthcare and the public sector.
R3 Corda is the leading technology stack when thinking about DLT. Aside from its extremely rich framework, it displays a significant quality; strong business coupling. Corda makes you think about the solution in terms of business flows and architecture, allowing you to deeply understand the system design before you start writing code. This process enables us to write better code and thus better systems and do this more naturally even within the complex landscape of a DLT ecosystem.
We are moving from a centralised thought process to the more versatile way of doing business on a densely connected grid. In the process, we will begin to see the benefits the ledger has to offer, those of transparency, traceability, immutability, immediacy and security. As we start storing more and more data in the ledger a familiar question will rise in mind. How do we turn all this data to insight?
The Use Case
Blockchain Digital was the first consultancy to recognise how Corda blockchain could be used to solve the problems of the property sector, and our project with the UK Land Registry has been recognised globally. As we have started to look more and more at the industry, we realised that a natural use case candidate would be deploying analytics on property valuation in Corda.
This article will take you through some early work, ‘thinking out loud’ around how an analytics node might be deployed on a Corda network. The simulated scenario we are using is that of a property owner who wishes to be represented from a real estate agency and list her property at a specific price in the market. For the sake of simplicity, we assume that a property has a single significant parameter that drives the price and that would be its floor area. We envision the existence of an analytics node within the ledger grid that we call the Seer node. The Seer node has a wider view of the ledger allowing it to train a regression model off-the-ledger on properties already listed in the ledger.
The forecasting algorithm
We simulated a dataset of 300 properties whose states were injected in the ledger through the Web API that our Corda solution exposes. The parameters that were used to describe a property include the property ID, the floor area, and a placeholder for price. The data State that represents a single property in the ledger looks like:
data class PropertyState( val owner: Party, val seer: Party, val propertyId: Int, val price: Int, val floorArea: Int,
override val linearId: UniqueIdentifier = UniqueIdentifier()) :
LinearState, QueryableState {
override val participants: List<Party> = listOf(owner, seer)
}
We used polynomial regressions as the algorithm genre for price forecasting. A 3rd degree polynomial regression was used and its response to the simulated dataset and iterative behaviour can be seen in the following figure.
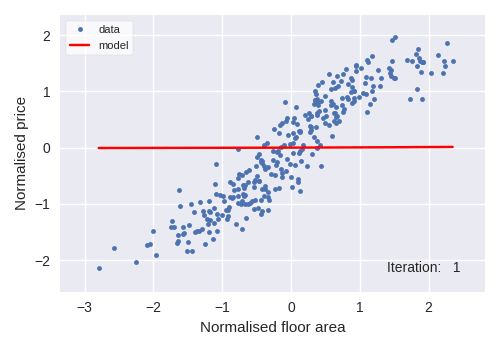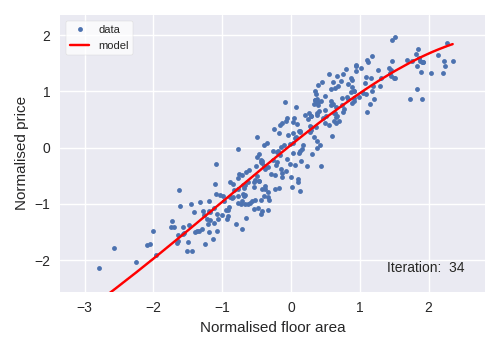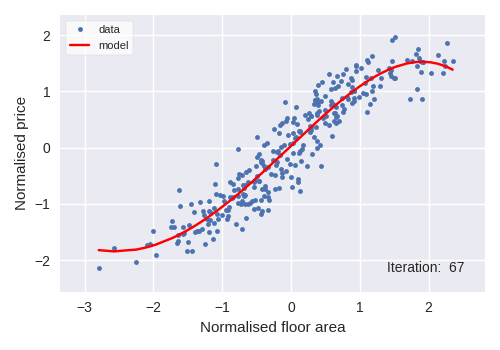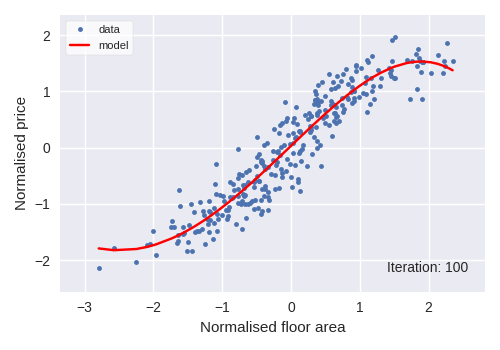
A 3rd degree polynomial regression of property price with regards to property area would look like:
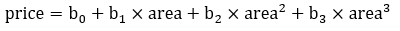
Storing the model in the ledger
In their essence, and this might not hold true for the entirety of econometrics and ML algorithms, the output result of a regression training process will resemble some kind of mathematical formula. In our case, if we wanted to store and use the trained formula for calculations predicting the fair price of a property given its floor area all we would need would be the 3rd degree betas b0, b1, b2, b3. We can therefore design a Corda model state that could store these parameters and it would look like:
data class ModelState( val seer: Party, val owner: Party, val modelId: Int, val b0: Double, val b1: Double, val b2: Double, val b3: Double,
override val linearId: UniqueIdentifier = UniqueIdentifier()) :
LinearState, QueryableState {
override val participants: List<Party> = listOf(seer, owner)
}
This Corda state would be governed by the Seer that would be responsible for keeping it up-to-date and circulate it to all involved participants in the network.
Forecasting Property Prices
Once a node has access to a property state and the model state it could call a forecasting flow that would bind everything together. The flow would consume the model state and the property state and run a function implementing the pricing polynomial. The forecasting flow could extract the explanatories used for the calculation, in our case area, from the property state and build the formula to the degree of the polynomial using betas from the model state. The function could look like:
private fun predictPrice(inputPropertyState: PropertyState,
inputModelState: ModelState): Int {
val priceHat = listOf<Double>(
inputModelState.b0,
inputModelState.b1,
inputModelState.b2,
inputModelState.b3).foldIndexed(0.0, {ix, priceHat, next ->
priceHat +
next* Math.pow(inputPropertyState.floorArea.toDouble(),
ix.toDouble())})
return priceHat.toInt()
}
After the calculation, a new output state would be stored in the ledger with the updated forecasted price of the property.
Reflecting upon the future of AI in DLT
This work is an early stage prototype with some initial thoughts put on design paper and implemented in Corda. There are many improvements that can be done. An important one would be refactoring the model state into a reference state. Reference states that will be introduced in Corda 4.0 are states that do not get consumed from transactions in the ledger but act as input parameters that stay relatively stable within the life-cycle of the application. The model state can be a good candidate for such a structure because ML algorithms are usually not continuously trained but their structure gets batch updated, something that could happen e.g. every end of week.
Other future thoughts include researching the structure of the grid itself that might be able to not only simplify analytics problems but also help naturally increase the accuracy strength and versatility of individual predictors. What if we wanted to build a region based house pricing model? Traditionally we might go about to partition the problem in regions, a process that can potentially include significant effort ranging from simple grouping operations on a local node to hot & cold cluster balancing on area indexing. In the context of DLT though things could naturally become simpler. With the existence of a single Seer node for every region of participants and the Network service using the locality data of the nodes to suggest the closest Seer in the group, then one could think of dedicated regional Seers employing only analytics on the data of that region. Taking the idea, a bit further and keeping in mind the concept of combinator functions we could envision the existence of a global Seer that consolidates data and statistics from regional Seers to provide a global view of the Ledger.
Conclusion
This is a first of a series of articles on possible AI implementations using Corda. Blockchain Digital will remain active in the context and will continue to experiment on different designs and prototypes within the different genres of ML such as classification and clustering as well as different ways of storing and using them in the ledger.