Monitoring Corda Nodes (Part 2)
April 16, 2018
Monitoring Corda Nodes (Part 2)

With the launch of Corda 3.0 bringing production readiness and with several projects going into production on Corda in the near future, we are digging in to some of the issues around running Corda in real production networks. In this second part we continue our exploration of monitoring with respect to Corda nodes.
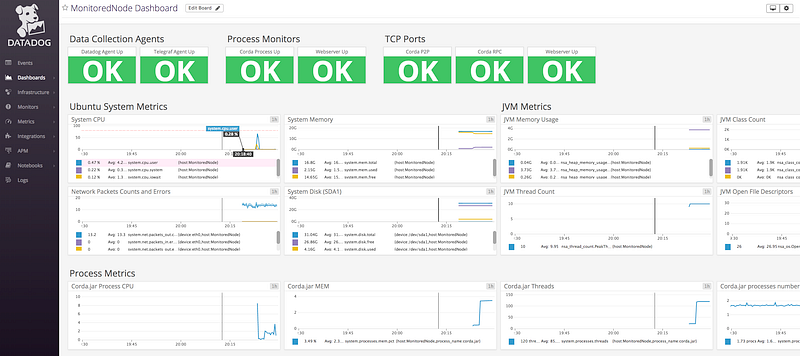
In Part 1, we set up the data collection of a series of metrics and monitors for a Corda Node running on an Ubuntu virtual machine on Azure. We are now going to configure a dashboard and alerting for these metrics so we can monitor our node and be notified automatically if something goes wrong:
We are using Datadog and have configured the agent which should be sending data to the application. Log in to the Datadog web application. Click on Dashboards>New Dashboard and fill in the name for your dashboard:
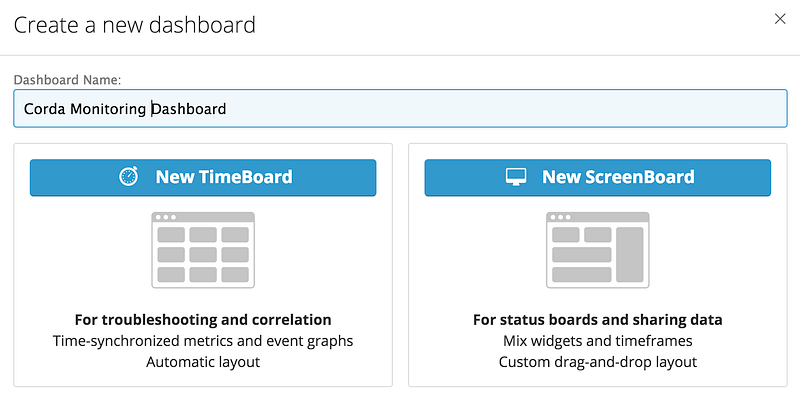
Select ScreenBoard and you will enter dashboard edit mode.
The first thing we will add is a check that the monitoring agents we configured in Part 1 are actually returning data. Drag a “Check Status” widget from the bar (scroll along) to your dashboard.
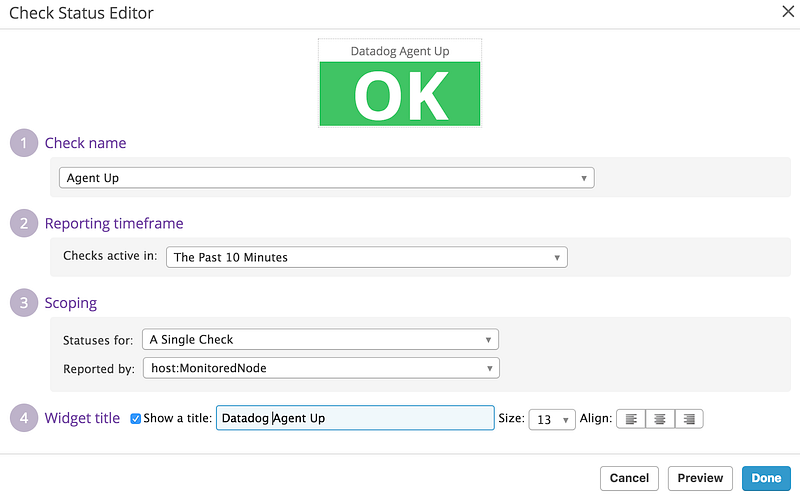
Make sure the scope is set to your host machine in the “Reported by” field. If the agent is returning data to the backend the status indicator will show a green OK. Click on “Done” to add this indicator to the dashboard (note you can drag it to where you want it on the dashboard).
Now we can add a status check for the telegraf agent in the same way. This time however select “Process Up” from the “Check Name” field and then choose the telegraf process monitor for your host from the “Reported by” field. You can go ahead and add status checks for all the monitored processes (e.g. Corda.jar) and similarly the TCP checks we set up in tcp_check.yaml by selecting TCP in the “Check Name” instead of “Process Up”.
If everything is working then all the monitors will show green:

We can make sure the dashboard is working by stopping the Corda processes. Wait up to 10 minutes and your status monitors should update:
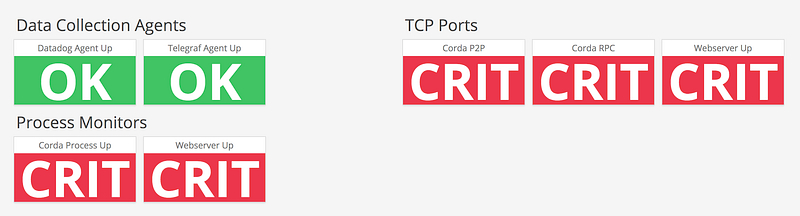
Our agents are still reporting data but now our Corda processes and TCP ports are showing as down.
Setting up Alerting
Before we get into visualising time series metrics let’s take a detour into setting up status check alerts which correspond to the status check indicators we just added to the dashboard. Setting up alerts (or monitors) in Datadog is quite straightforward. In the left sidenav click Monitors>New Monitor.
Select “Process” from the monitor type list. Pick “process: corda.jar” from the process dropdown. Make sure it is scoped to your host machine. Leave the alert conditions as the defaults for now — this is a fairly simple alert: send a notification if the status check fails. Alerting conditions can be refined later if you find this is alerting too frequently.
Make sure to give the alert a meaningful name so whoever gets notified has a chance of understanding what happened. A really good alert will include details on likely severity, possible causes, potential mitigations (e.g. restart the service), links to the appropriate monitoring dashboard (a jumping off point for investigation, diagnosis, correlation and root causing), who should be notified (escalations) and links to the relevant playbook or operations guide.
Finally set up where the notification will go. For now you can go ahead and add your email address, or the email alias of your on-call group. You can also configure a number of integrations to services like Slack or dedicated on-call tools like VictorOps or PagerDuty, but we won’t cover those here. Click “save” to create the monitor.
Monitors for the other status checks can be configured similarly. These are quite straightforward alerts in that they fire if the status check returns critical and not if it doesn’t. Metric alerts are only slightly more complicated and require the specification of thresholds and durations which if exceeded will trigger the alert. These can be set up in the same way by selecting “Metric” from the Monitors tab:
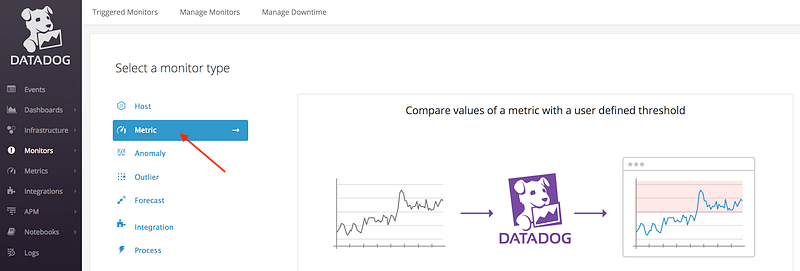
Visualising time-series metrics
Now lets switch back to our dashboard and add some graphs. We are going to add 3 categories of metrics: system metrics from the Ubuntu virtual machine, JVM metrics and finally Corda application and CorDapp metrics.
Let’s start with system metrics. It might seem overkill to collect metrics at the system level if we can view the JVM and application directly, however taking a layered approach to monitoring can help when something goes wrong to isolate the problem quickly. For example if you have a problem connecting to your node RPC interface but by looking at your monitoring dashboard you can see the metrics for the host machine are OK then you can isolate the problem to the application straight away. If however there is a problem affecting, say, the network or the host machine then it is easy to isolate that and mitigate appropriately and rapidly. Monitoring host machine metrics is also helpful for capacity planning purposes to make sure your resources are provisioned correctly. Do you have enough disk space for the application? Are you hitting limits on RAM? Are you underutilising and therefore paying too much for your cloud instance?
Go back to the dashboard and click on “Edit Board”. Drag and drop a “Graph” widget onto the dashboard. In the graph editor choose “Timeseries” for “Select your visualization”. Select “system.cpu.user” in the Get field of the metrics. In the From field select your host. We can add several lines to the same chart so as there are several metrics associated with CPU utilisation click on “Add metric” and add lines for “system.cpu.system”, “system.cpu.iowait” and “system.cpu.interrupt”.
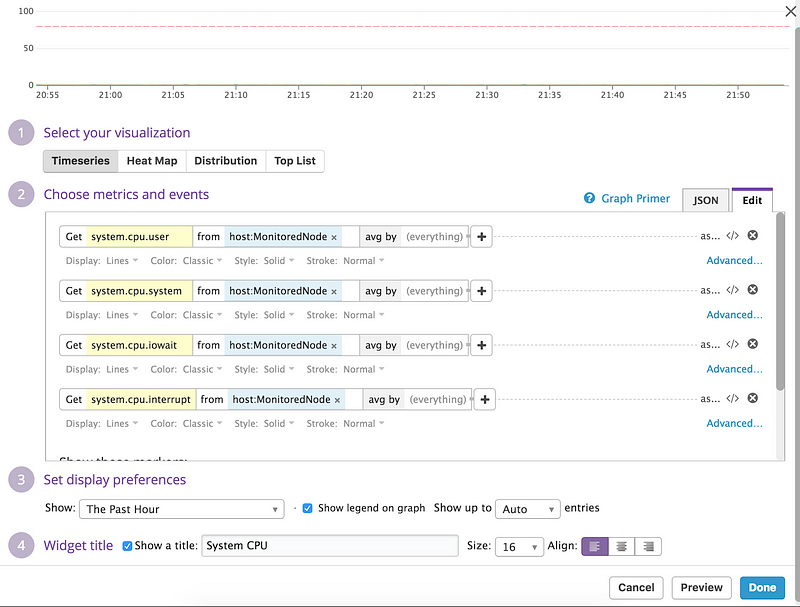
Set your display preference to “The Past Hour”. Enable the legend, give the chart a meaningful title and click “Done”.
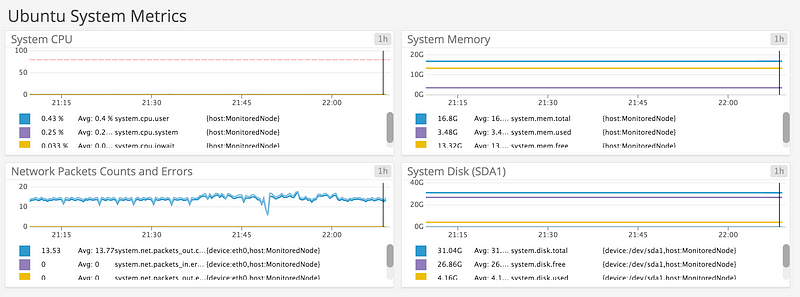
In the same way add charts for system.mem (memory), system.net (network), system.fs (filesystem), system.disk (disk) and system.io (IO).
The process monitors we set up earlier allow us to look at the resource usage on a per-process basis. For example if you want to see the CPU usage of the corda.jar process you can add a timeseries chart for this:
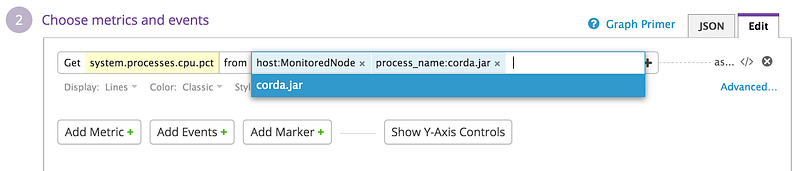
Simply select the system.processes.cpu.pct metric and scope by host and process as above.
We can add timeseries charts for JVM metrics in the same way. These metrics will be identified by the names we configured in part one in the telegraf.conf file settings for Jolokia.
Good things to track from the JVM include CPU/Memory, thread and class counts and garbage collection metrics.
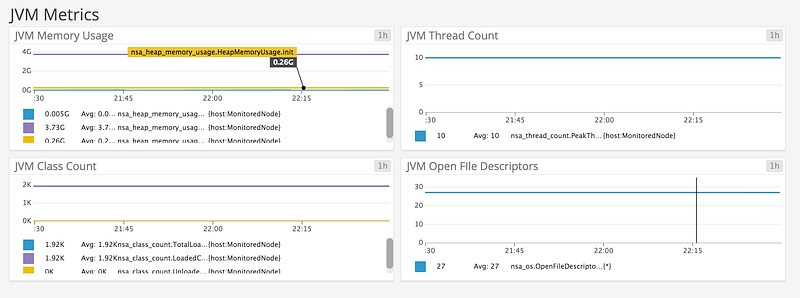
Finally we can add charts for the Corda specific metrics. The Corda application metrics focus on the flow framework allowing you to check the number of started, inflight and finished flows. This will tell you if flows are failing to complete which can point to problems with the Cordapps you are running on your node. We will be adding more application metrics to Corda in subsequent releases.
This should give you enough to get started with monitoring of Corda in production, but we are only just scratching the surface of a proper monitoring setup here.
Next Steps
1, Read chapter 6 of “Site Reliability Engineering” on “Monitoring Distributed Systems” for a great background discussion on monitoring and alerting in production.
2, Set up uptime checks with a black box provider such as Pingdom or Catchpoint. These services will also integrate with Datadog and other monitoring services.
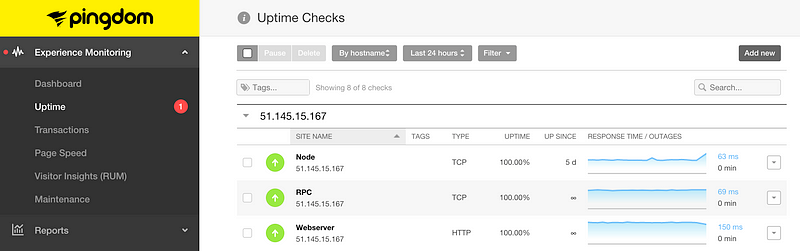
This uses a TCP check like we configured earlier but from a network of remote locations. You can specify specific locations for originating checks. These services can also measure latency from specific locations. (Note that these are paid-for services. As an alternative you can configure a TCP check as we did previously from a different machine in a remote location.)
3, Set up logging. Monitoring is just one aspect of comprehensive production coverage. When a problem is detected it is important that the appropriate logs are being collected and exported for debugging and investigation purposes.