Experimenting with Corda Attachments
March 02, 2020

Summary
Corda’s stellar transaction throughput has already been examined and documented. In this article we discuss a separate experiment that measures Corda’s transaction rate with attachments. I created one CorDapp called GenerateMockAttachments which would automatically create a set of test files on a source node. Once generated, I used another CorDapp called TriggerAttachmentDownload which sent a transaction containing an attachment hash from the source node to a target node causing the target node to download the attachment. Each of these requests were done using Python coroutines to make asynchronous REST calls to a proxy server which relayed the request as an RPC to a Corda node.
The results of the experiment revealed:
- I was able to achieve 49~ Tx/s with 1MB attachments and 45 Tx/s for 10MB Txs.
2. Caching attachments can greatly improve throughput.
3. Regarding attachment throughput, Spring is more performant than Braid.
4. The more memory available, the more threads the node can handle; thus, increasing throughput.
The Problem
Users including large files within a Corda transaction should consider how those files can affect their application’s throughput. Take the use case of data set sharing for example. When a data set first starts out it could be quite small, let’s say 1MB. But as data is appended over time, the set might grow to a size of 10MB or more one day. The question that inevitably arises is what kind of performance can we expect from transacting with such large files?
Besides file size, it would also be interesting to compare the results of two different proxy servers. Proxy servers like Spring and Braid are implemented to facilitate the P2P communication between Corda nodes such as sending transactions. Although Spring has been the go-to solution for Corda implementations, there is another solution rising in popularity called Braid.
Analysis
Spring vs Braid:
To compare server performance, I conducted four tests that measured the total elapsed time for 100 attachment transactions to complete. Each test used the same source node (Issuer node-US East), an attachment size of 1MB or 10MB, and a domestic (RecipientB-US East) or international (RecipientA-CA Central) target node. To initiate a transaction, I concurrently called the respective server’s TriggerAttachmentDownload flow which would cause the source node to load the (non-cached) attachment from disk so that the target flow can then read and write the data to its disk.
Being that Braid doesn’t currently have a parameter to adjust the threadPoolSize, my tests were limited to the eight concurrent threads that Braid’s underlying framework (Vert.x) uses by default . This also meant that I had to run Spring at an eight thread maximum as well if I wanted to actually measure which performed faster under the same constraints.
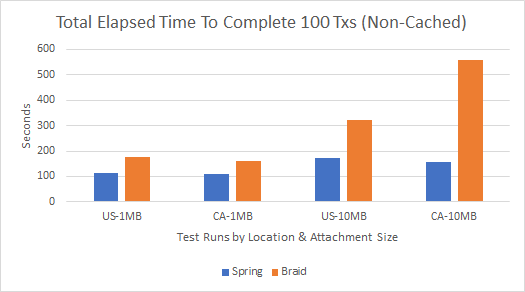
Spring Pros:
- Consistently faster than Braid in regard to attachment size and latency due to node proximity.
- Number of threads that can be processed are only limited to your node’s available memory.
Spring Cons:
- Requires some research to understand how to use Spring annotations.
- Requires development time to create and test your REST endpoints.
Braid Pros:
- Great for quick POCs since it doesn’t require any setup time or prerequisite knowledge besides downloading the jar file.
- Using Open API, Braid will inspect your CorDapps folder and your flow parameters to automatically create REST endpoints for any application to call your flows so you can focus on CorDapp development.
Braid Cons:
- Although Braid’s underlying framework can handle a lot of concurrency using a small number of kernel threads, Vert.x’s golden rule says “Don’t block the event loop”. Because each of our requests requires a blocking thread to write our attachment to the target node’s disk, that means all my tests were limited to only eight threads.
Cached vs Non-Cached Attachments
Now that I had decisive winner in regard to server performance, it was finally time to take off the governor and test for throughput with no threading restrictions on my Spring server. Going back to our original example use case of data sharing, most of the transactions that would take place involve reusable attachments albeit the occasional update to the data set. Therefore a cached approach where said attachments are pre-loaded is optimal as the source node sending the transaction isn’t required to re-request the attachment from the database.
To cache my attachments prior to the test, I sent a transaction with each of the attachments to a node I wasn’t going to be testing with. For example, if I was measuring RecipientB, I would send the transactions first to RecipientA.
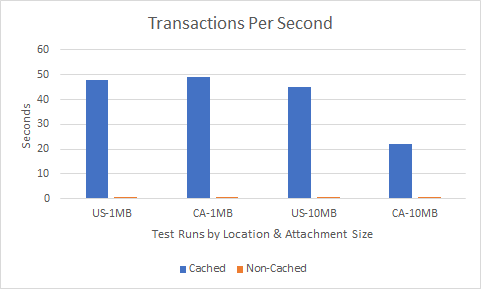
Figure 2 above shows the dramatic effect that pre-caching your attachments can achieve. Not only was throughput 50 times faster than non-cached transactions, but the comparison of the results from the US-1MB test to that of the US-10MB shows only a 7% drop in performance while transacting with attachments that are ten times larger in size.
Further Work
- Run more tests between 1–10MB as well as 10MB-50MB to find the limit for a node with a Java heap size of 8GBs.
- Scale up my node’s respective VMs in regard to both available cores and RAM. With more memory, my node would be able to handle more threads which would handle more transactions therefore increasing throughput.
- Each of my tests used the default H2 database that Corda nodes come with. It would be interesting to see how other databases like PostgreSQL or Microsoft SQL Server can affect throughput for transactions with attachments.
Conclusions
- Although its not obvious from the 1MB test sets, latency’s effect on performance was highlighted in the 10MB tests (Figure 1- Braid US-10MB vs CA-10MB and Figure 2- Spring US-10MB vs Spring CA-10MB) since there are more data packets to transfer that each incur some constant latency.
- Caching is essential for applications that will be transacting with attachments often and developers should look to leverage this approach whenever possible to increase performance.
- Scale up your VMs for more throughput. By increasing the memory available to a node, the more files can be processed concurrently and the larger these files can be. I tried a couple of tests with 100 concurrent transactions containing 50MB attachments and my node crashed with a complaint about the heap size (running at 8GBs max) after sending around 16 transactions.
My recommendation therefore is to use Spring server for P2P communication between nodes and allocate sufficient memory for the performance you expect when transacting with attachments so that your nodes can handle the amount of concurrent threads your application will be throwing at it. In my case, an 8GB heap size was sufficient to send 100 concurrent transactions with file sizes as big as 10MB. Also if possible, try to reduce the distance between the source and target nodes to avoid latency costs.
Appendices
Libraries Used:
- Python: Asyncio , Aiohttp, timeit
- Java Version: 1.8.0_242
- Corda Enterprise 4.3.jar
- Braid-server-4.1.2-RC13.jar
- My CorDapp, Spring Server, and Python repository
Network Setup:
To setup my test environment, I leveraged the network bootstrapper with maxMessageSize and maxTransactionSize set to 200,000,000 bytes and created four nodes:
- Notary node deployed in US East
- Issuer node to act as the initiator/source for each transaction — deployed in US East
- RecipientA node to act as a international target node — deployed in CA Central
- RecipientB node to act as a domestic target node — deployed in US East

How to Reproduce:
- Once you have your nodes deployed, start each of your nodes with:
java -Xms8g -Xmx8g -jar corda-4.3.jar
2. Start and connect your proxy server to the Issuer node:
Braid:
java -jar .braid-server-4.1.2-RC13.jar [HOST:YOUR_PORT] [NODE_USERNAME] [NODE_PASSWORD] [YOUR_PORT] [OPEN_API_VERSION] [YOURNODE_CORDAPP_DIRECTORY]
Spring:
java -jar .corda-webserver.jar — server.port:PORT — config.rpc.host=HOST — config.rpc.port=RPC_PORT — config.rpc.username=USERNAME — config.rpc.password=PASSWORD
3. Generate a test set of attachments by running generate-test-files.py with your desired parameters.
4. Use the output from the previous step as the hashed_files_list in the async-rpc.py. These hashes will be sent to the target node in a transaction and used to reference the attachments we want the node to download. Once you edit this, you should then change the name of the receiver in your JSON object to that of the node you are targeting.
Braid:
json ={
"receiver": {"name": "O=RecipientB, L=East, C=US",
"owningKey":"GfHq2tTVk9z4eXgyREZSNrh9oZRPk9beKuUx7Aeu1sKLTTgqyjAwMyjyNE4D"},
"attachmentHash": hashedFile}
Spring:
json ={"receiver": "O=RecipientB, L=East, C=US",
"attachmentHash": hashedFile}
5. Once you’ve updated your script, execute it with the following command to save the output to a file:
python ./async-rpc.py > ./your_directory/my-test-01.txt .
Once completed, you can examine the results of your test in the output file you save it to. There will be a line for each request’s time as well as the total elapsed time for all requests to complete.
Author: Jonathan Scialpi, R3
Experimenting with Corda Attachments was originally published in Corda on Medium, where people are continuing the conversation by highlighting and responding to this story.