Corda Kubernetes Deployment (Part 2 of 2)
April 02, 2020

TL;DR: Deploying Corda Enterprise and Corda firewall in a Kubernetes cluster and seeing how it all works!
Introduction
In my previous article, I introduced the Corda Kubernetes deployment, which makes it possible to deploy Corda Enterprise in a Kubernetes cluster using Helm charts. The goal of the Corda Kubernetes deployment is to make the journey into production an easier one.
I encourage you to read the first part of this article series if you haven’t, but to give you a summary, we started by understanding the complexities of a Corda deployment and the need to automate the process. Then we looked at the overall architecture picture and the prerequisites of a Kubernetes deployment. Finally, we made an initial registration of the Corda node using the Corda Kubernetes deployment and registered our node on the network. This was enough to set the stage, but now we need to perform the actual deployment.
In this article, we will learn how to use the Corda Kubernetes deployment. The deployment can be configured and customised based on the individual project requirements. We will start by looking at the configuration options, then we will see how we can compile and deploy the solution into a Kubernetes cluster. The main part of this article will focus on running the solution in a Kubernetes cluster and investigating potential issues that may arise throughout the deployment process to give you the tools you need to be successful in your deployment journey.
Let’s get started!
Configuration
We use Helm to set up all the configuration required for deploying the Corda node. This works out to just editing one file, the “values.yaml” file. Let’s review a sample of the “values.yaml” file and see what we would usually be customising in this file.

The 3 main sections we should configure are as follows:
- Setup — defines the different choices we can make for the deployment, should we deploy Corda Firewall and if so where, should we use Hardware Security Modules (HSM) and so on
- Config — defines the technical details of the deployment, the resource names to use, the IP addresses that are reserved and the username and passwords to access external resources such as persistent storage
- Corda — defines Corda specific parts of the deployment, mainly relating to the “node.conf” file that configures how Corda will run
There are predefined values for most options, but some will need customisation based on your deployment. The values that I anticipate you will have to customise are defined in the Github repository.
The value for the option “corda.node.conf.legalName” should define the X.500 legal identity name of the Corda Node, this should follow the naming conventions of the Corda Network and the Node naming guidelines.
Other than that, you can customise the file based on your deployment environment. For example the Corda firewalls float component would require to have a publicly accessible IP address in order to accept incoming connections from other nodes on the network, so you can define the publicly facing IP address in the “values.yaml” file.
Helm Compilation
Since we already tackled the initial registration step in the previous article, we shall skip that step and move straight into the next one, which is Helm compilation. Helm compilation is performed by executing “helm template” command, which is wrapped in a script called “helm_compile.sh”. Compilation is the act of taking the set of Helm templates, applying the values defined in “values.yaml” file and generating the final set of Kubernetes resource definition files. These files can be directly applied to a Kubernetes cluster to create the requested resources.
Kubernetes Resources
Let’s review what resources this deployment currently uses and for what purpose:
- Service — the Kubernetes Service is defined for the Corda Node and the Corda Firewall components, namely the bridge and the float. The main reasons to use a service is to define the ports and IP addresses to use.
- Deployment — the deployment resource is the main workhorse of the Kubernetes deployment. It defines what a pod is and does, what Docker image it will be running, what physical resources it has available (for example amount of memory/CPU). In addition, it defines mount paths that are required to fulfill persistent storage requirements.
- PersistentVolumeClaim, PersistentVolume and StorageClass — by using persistent volumes we can define the persistent storage to use for the node, bridge and float.
- Secret — there are some data that should not be kept within the container, but which are required in order to have a fully working deployment. Examples of such secrets are the authentication required for persistent storage access and also the authentication for the container registry.
- ConfigMap — by use of a config map we can insert necessary information into the running pods of the deployment in a read-only manner. Such data could be the “node.conf” file, but also the certificates required. The certificates could further have their private keys stored in an HSM to add additional security.
Deployment
Deploying the compiled Kubernetes resource definition files can be done in two ways, either by letting the “helm_compile.sh” script perform it automatically, or by running “kubectl apply -f” command targeting the folder. This effectively copies the definition files into the Kubernetes cluster, where Kubernetes takes over and starts taking actions based on those files. Kubernetes would normally be setting up the resources, routing them to each other and to external resources, making sure everything gets started up correctly, and if not, reporting the issues. We will cover investigating issues in a later section. It might be worth it at this point to make sure we enable Secure Shell (SSH) access to our deployed node, this will be useful in testing later in this article. Please note that SSH access should be disabled in production.
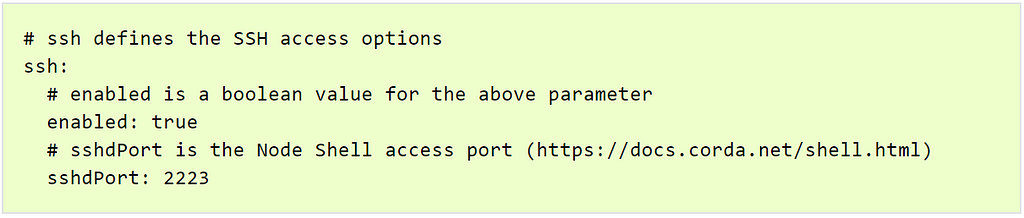
Secure Shell (SSH) Node Access
In order to enable SSH access to our deployed Corda node, we should make sure to define the following in the “values.yaml” configuration file.
Running the Services
Let’s see what happens as Kubernetes spins up the services. We will start by verifying that the pods are actually spinning up within the cluster first, this is done by running “kubectl get pods” command. The result will look something like this:

It is normal to see the pods with the following status:
- PENDING — which will be displayed while Kubernetes is downloading the Docker image for running the container and also connecting any other resources, for example persistent storage
- RUNNING — this means that the container has successfully pulled the Docker image from the container registry and connected to any additional resources and is now starting up the actual component, for example the Corda Enterprise node
- FAILED — is shown briefly in the case that the pod terminates. Kubernetes will automatically re-schedule and start it up again (going back to “PENDING” and into “RUNNING” status)
In addition, seeing a pod in the “PENDING” status for an extended period of time indicates that there is an issue with the pod, please see the next section for more discussion on this point.
Once we have the pods up and running, we would surely like to see how the starting up goes and what the pod logs, this can be done by the command “kubectl logs -f <pod>”.
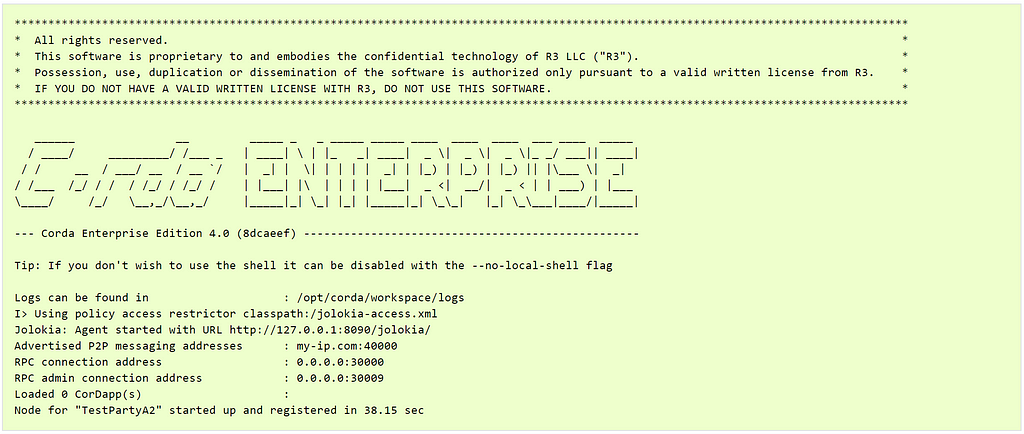
We can see examples of the Corda Enterprise node starting up in the following views:
The Corda Firewall bridge component starting up:

And the Corda Firewall float component starting up:
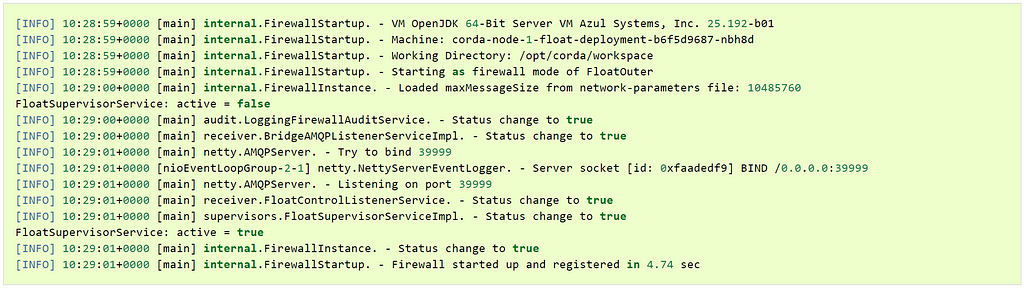
These are normal startup logs for these components and indicates successful startup sequences.Unfortunately, the Corda node Kubernetes pod does not produce the node logs directly to the previously mentioned command output. Therefore we have to dig a little bit deeper to understand what the node is doing as it is starting up and when it is running.
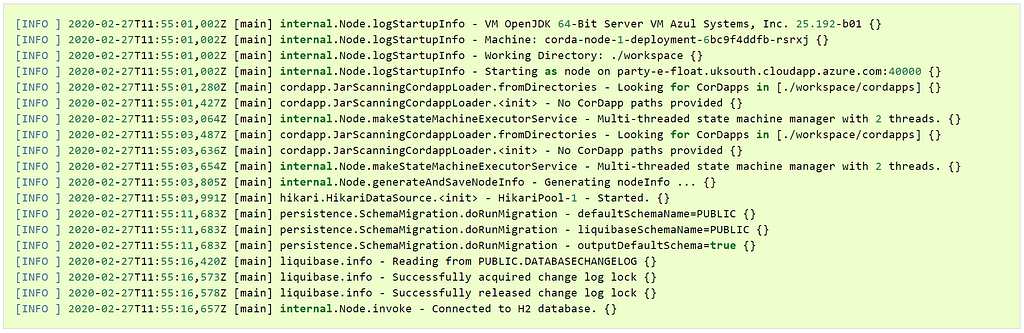
We can do this by logging into the pod which can be done in two ways. One is to enable an SSH connection into the pod. The other much easier way is to create a direct command shell into the running pod with the following command: “kubectl exec -it <pod> bash”. On Windows, you may have to prefix this command with the additional call to “winpty”, in other words: “winpty kubectl exec -it <pod> bash”. Once the command is executed, we will have a live shell access into the node and can execute commands as we normally would in a shell. We should change the directory inside the shell to “/opt/corda/workspace/logs“, find the node-logs file corresponding to the name of the Kubenetes pod container. Then you just execute a command to view the data, for example “tail -f -n 50 <log file name>”.
The output will list what the node has been doing, and we get a very similar view to the previous views from the bridge and the float:
Investigating Issues
We just looked at the happy path, where everything just worked and the components started up successfully without any issues. It is worth mentioning that when you set up a new deployment for the first time, that may not always be the case. You may encounter authentication issues to your persistent storage or to your external database, or you may have forgotten a previous step, for example pushing the Docker images to the container registry. These are just examples and not an exhaustive list, but in this section we look into how we can pinpoint any issues that may occur.
There are two important commands for investigating issues to keep in mind, “kubectl get pods” and “kubectl describe pod”.
The “kubectl get pods” command defines if the pod is starting up successfully or left in the “PENDING” state. We will cover the scenario where the pod remains in the “PENDING” state next, but have no fear, we will investigate what issues a running pod can encounter as well in a later section.
Troubleshooting Issues For Pods In “PENDING” Status
So, the pod is in the status “PENDING”, and you want to know why that is. Let’s start by running the “kubectl get pods” to get the names of the running pods and then we will use the describe command.
The “kubectl describe pod <pod>” command will list the information that Kubernetes stores about the pod, and what actions and events the pod has encountered.
The output will look something like this:
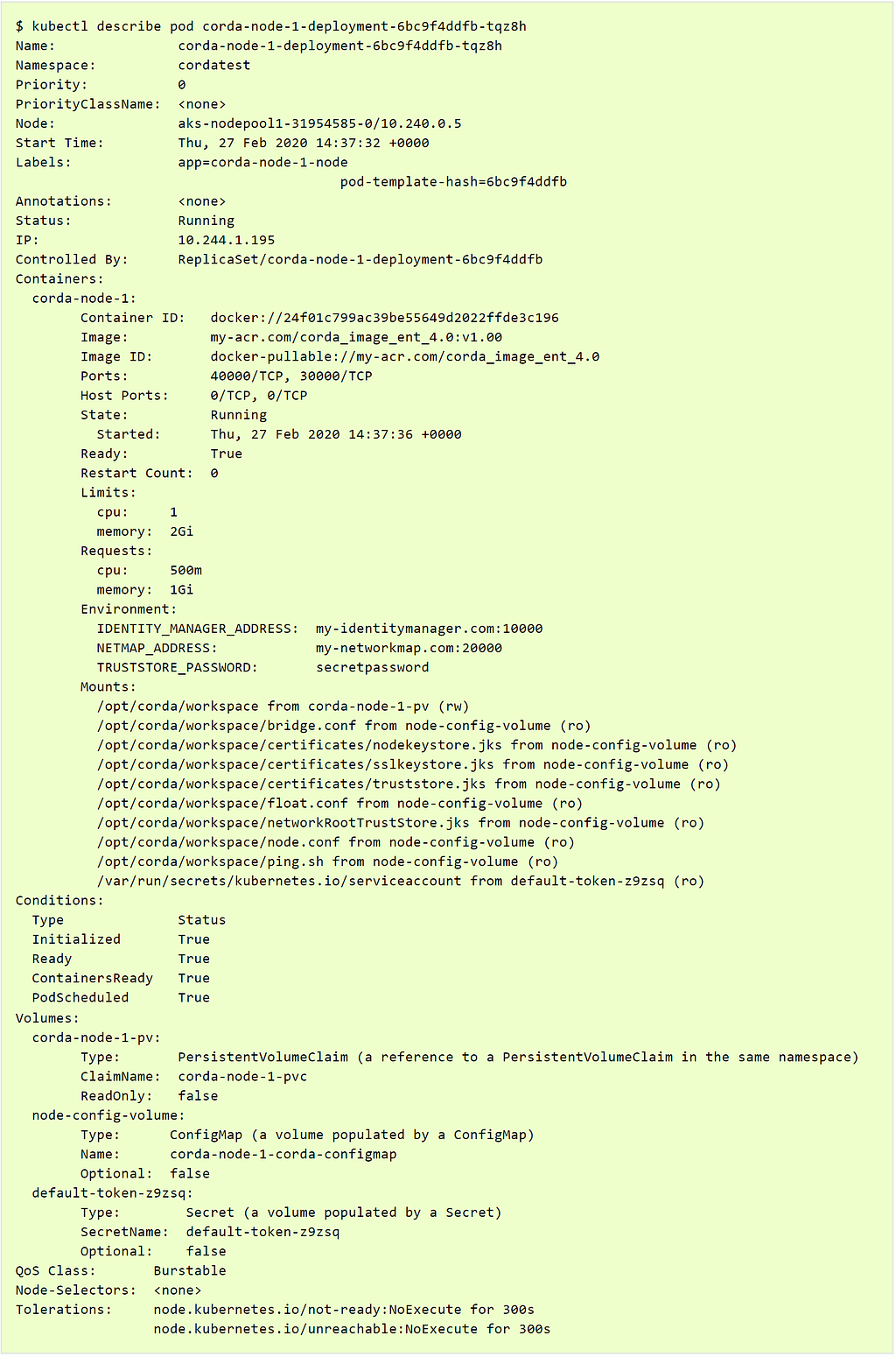
As you can see, the output is always listed, and it’s good to verify that the assumptions around the deployment are correct. However, the main part that is only outputted if there are some recent events/issues is the “Events” section as seen below:

This is the most important part of the describe pod command in my opinion. It will give quite a clear description on what the pod has done up until the eventual issue. And even in case of issues, the event description will be quite clear in what has gone wrong. It may not state directly how to resolve it, but with the error message and a bit of investigation online, it will be possible to pinpoint and resolve the problem.
Some common issues you may encounter include:
- Errors pulling Docker images — this can either indicate that the container registry server address is invalid or not reachable due to for example permission issues. It can also indicate that the Docker image name we are trying to pull does not exist yet
- Errors binding the persistent storage — this is usually due to incorrect authentication details, but could also indicate that the storage account is not reachable from the Kubernetes cluster
There are other issues, but we won’t go deeper into all the possible issues that can appear. You should now be comfortable in investigating the issues around “PENDING” pods.
Troubleshooting Issues For Pods In “RUNNING” Status
So, you now have your pods up and with status “RUNNING”, but they still aren’t working in end-to-end workflows. What could be the problem? How should we approach the investigation of this type of issues?
In this case we will have to start digging into the details of the deployment and the logs that all Corda components provide on a regular basis.
Let’s recall (from the previous article in this series) how the connections play out. We have the bridge connecting to the node and then to the float. Once that connection has been established and only then, will the float open the listening port for external connections. If any part leading up to that fails, we will not have a complete communication tunnel.
So, how do we discover where the problem lies? By investigating the logs that the components produce. Let’s always start with the bridge component, we have to know if it has been successful in connecting to the node first and foremost.
Let’s start off by checking what the logs would report in the case that the node is not reachable (for whatever reason).

We can see clearly that the bridge is trying to connect to the node on a specific port (40000 in this case), but the connection fails. It is important to note that the error message cannot define exactly what the connection issue could be. The message would remain the same if the node service is not running at all, or simply because the network tunnel between the two components is not reachable. It remains up to the reader to pinpoint where the issue lies, by first checking if the two services are up and running in a stable manner. If they are, then performing ping, telnet and general connectivity tests to see where the problem lies. There is more help on this in the Solutions site documentation.
Once we have pinpointed the issues and fixed them, we will be able to see the following successful log messages. These messages indicate that the bridge to node connection is working correctly.

After the bridge has connected to the node, the next step is for the bridge to connect to the float. In the bridge log file we can see if there is a connection issue, as highlighted below:

Troubleshooting this part is straightforward and similar to the previous section on bridge to node connection issues. We check that both the bridge and float services are in running state in the Kubernetes cluster. If they are, then perform a ping between them to ensure that the connection is possible. If the basic connectivity is there and working between the two pods, we could assume that the connection is a TLS connection issue. You may recall from the previous article that the bridge and the float use a separate TLS PKI hierarchy. If there is a misconfiguration of these certificates, the connection will not be successful.
Once the bridge makes a successful connection to the float, the following messages will appear in the log file:
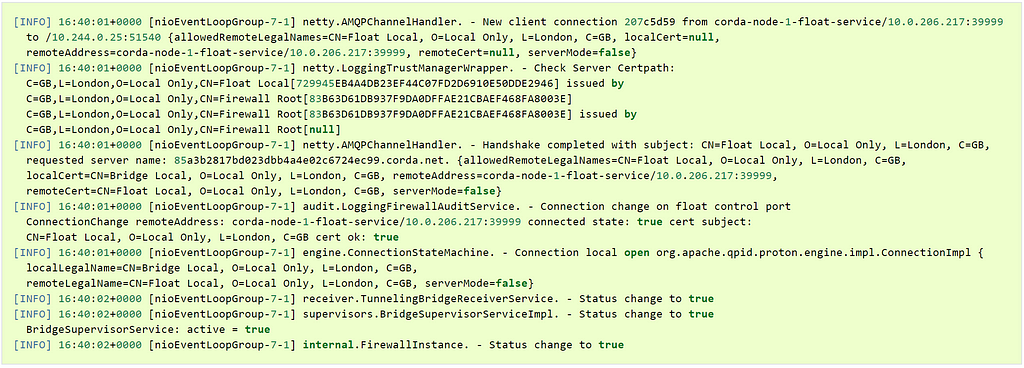
Now that the bridge has successfully connected to the float, the float will open the listening port for other nodes on the network to connect to. This is the final point where things can get more complicated, because the float is commonly protected by an external facing firewall. We need to make sure that the port that the float is listening on is reachable from the internet. This can be accomplished by ping/telnet commands, or by connecting to this node with another Corda node.In this section we learned how to investigate connection issues from the pods viewpoint by looking at the logs produced by each component. We should now have a fully operational node which can transact with other nodes on the network, let’s see how.
Corda Transaction Testing
By now we should have a working deployment, regardless if we had to sort through some issues while getting everything up and running or not. Next, we want to perform some test transactions on our deployment. We will do this by executing transactions from our node to other nodes on the network using the shell. It is recommended that you already have a second node running, alternatively you can deploy a second node in another Kubernetes namespace.
Setup
You should now have two nodes that can execute some flows between each other.
Let’s start by connecting to the first node’s SSH port to gain access to the node shell. We do this by running a regular ssh connection command: “ssh -o StrictHostKeyChecking=no user1@localhost -o UserKnownHostsFile=/dev/null -p 2223”. Please note, localhost points to the current computer. In case you are not connected to the Kubernetes pod, you can gain access to the pod with the command we introduced previously in this article “kubectl exec -it <pod> bash”. You can also connect from your local computer if you use Kubernetes port forwarding feature, which essentially delegates the connections from your local computer to the Kubernetes cluster, to a specific pod. This can be done by running this command: “kubectl port-forward <pod> 2223:2223”.
Regardless how you gain access to the node shell, you should be greeted by this text in your terminal window:

If you type “help” in this interactive shell, you can get a list of available commands.
We will be using the Corda finance jars in this example to demonstrate the connectivity, but any sample that performs a visible operation between two nodes is acceptable for this phase. You can find a list of example CorDapp projects that you can build in the Corda samples repository. You can download the finance jars directly from here Finance Contract CorDapp and Finance Workflows CorDapp. In order to place them into your deployment you have two options:
- The easy and recommended way: by executing the script “output/corda/templates/pre-install.sh”. This script will simply copy anything in your “helm/files/cordapps” folder into the nodes persistent storage folder
- Manually gain access to the persistent storage used by the Corda node and then copy the new CorDapps there. This may require some additional cloud configuration
Please restart the Corda node to make sure it has loaded the CorDapps. If you end up using developer CorDapps, you must also enable “allowDevCorDapps” in the “values.yaml” file to make sure we can load these unsecure CorDapps. We can verify that the CorDapps are loaded by inspecting the Corda node Kubernetes pod with the “logs” command as previously shown, the output should list that the CorDapps were successfully loaded.
Executing The Tests
Now we can start executing our flows in the shell. Let’s get started by issuing some cash to ourselves with the following command (please replace the notary name with a valid notary name on your specific network, you can list the valid identities with command “run notaryIdentities”):
flow start CashIssueFlow amount: $1000, issuerBankPartyRef: 3
notary: Notary
This should issue the cash, an example of a successful output looks like this:

Then we can send the cash over to the other node, in this example we use the node named PartyA2:
flow start CashPaymentFlow amount: $30, recipient: “O=PartyA2,
L=London, C=GB”, anonymous: false, notary: Notary
An example of a successful output of this flow should look like this:
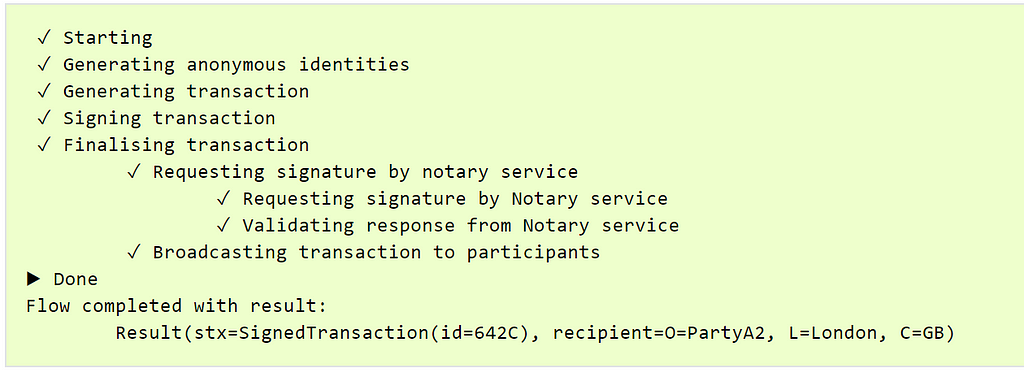
This means we have sent some of our hard-earned cash (self-issued) over to the other node. It is on this step that we are most likely to see any issues if our deployment is not set up correctly. If the transaction hangs on requesting a signature from the Notary service, it means that we cannot reach the Notary node on the Corda Network. We should then run a manual connectivity investigation on the connections between our node and the Notary node. We can also look at the node logs for more information including some exceptions on connection failures.
Once we have sorted through any potential connectivity issues, we should reach the above success result and then we can move on to the final step.
The last step is just to verify that we reflect the payment in the vault as reported by the Corda nodes Vault Query:
run vaultQuery contractStateType:
net.corda.finance.contracts.asset.Cash$State
Example output as follows:
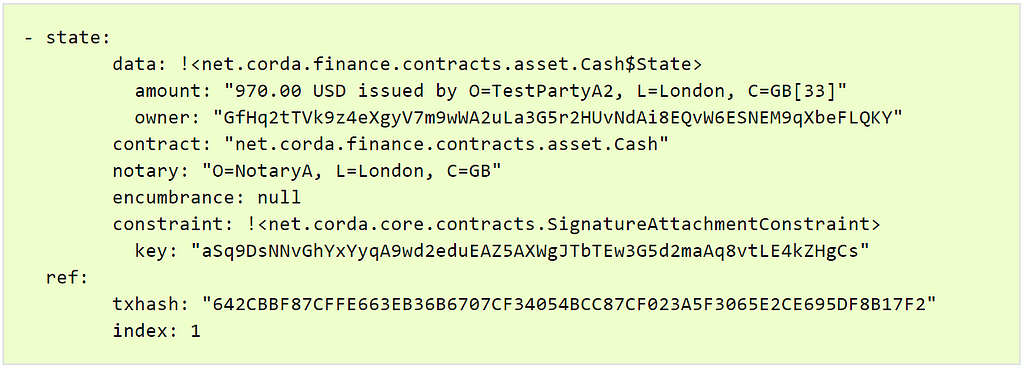
As we can see, we have a cash state in our vault, but it is $30 short of the $1000, in other words $970. This is expected, since we started by issuing $1000 to ourselves, then we paid $30 to another node, leaving us with the change $970.
This concludes our transaction testing on the Corda node deployment on Kubernetes.
Summary
In this article we deployed our Corda Enterprise node along with Corda Firewall into the Kubernetes cluster. We learned how to identify a successful start-up sequence of all the components, how to investigate any issues we may encounter along the way and how to solve them. Finally, we transacted some cash between our nodes which means we have a fully working node up and running in a secure manner.
My aim in creating the Corda Kubernetes Deployment and writing this article series has been to create an easier journey into production by showing you the different components of an enterprise grade Corda deployment, how to navigate the Kubernetes environment effectively using scripts/commands and how to deploy the full solution very rapidly.
It is my hope that with this solution and the provided documentation, you have gained valuable insight into how the Corda Enterprise components connect, start up and operate, and that you will be able to handle anything that comes your way.
Good luck!